Hello, is there anybody in there? Just nod if you can hear my EIGRP hello packets being multicast to 224.0.0.10….
Apologies to any Pink Floyd fans out there, but the opening line to Comfortably Numb describes perfectly what happens when an interface starts participating in an EIGRP routing process (well, not really).
As we know from CCNA study, the config to set up basic EIGRP is very simple. We just define the AS (Autonomous System) number, and which networks to advertise. We’ll use the following network as an example to illustrate the process:
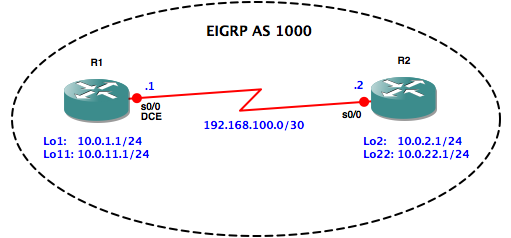
Let’s get EIGRP configured on R1 and get it advertising it’s directly attached networks. We’ll use all zero’s wildcard masks for the loopback interfaces, to make them as specific as possible, and turn off auto summarization (EIGRP is a classless routing protocol, but it will still summarize networks using classful boundaries by default):
R1(config)#router eigrp 1000
R1(config-router)#network 192.168.100.0 0.0.0.3
R1(config-router)#network 10.0.1.1 0.0.0.0
R1(config-router)#network 10.0.11.1 0.0.0.0
R1(config-router)#no auto-summary
Next, lets check that the network statements we’ve used above have enabled EIGRP on the correct interfaces:
R1#show ip eigrp interfaces
IP-EIGRP interfaces for process 1000
Xmit Queue Mean Pacing Time Multicast Pending
Interface Peers Un/Reliable SRTT Un/Reliable Flow Timer Routes
Se0/0 0 0/0 0 10/10 0 0
Lo1 0 0/0 0 0/10 0 0
Lo11 0 0/0 0 0/10 0 0
Remember that enabling EIGRP on an interface has two effects:
- EIGRP Hello packets will start being sent out of the interface to multicast address 224.0.0.10. This means that neighbour relationships (adjacencies) can be formed with other routers directly connected to the same subnet and using the same EIGRP AS number
- the network that the interface is part of will be advertised by the EIGRP routing process
To confirm that Hello packets are being sent, we’ll enable debugging of EIGRP packets:
R1#debug eigrp packets
EIGRP Packets debugging is on
(UPDATE, REQUEST, QUERY, REPLY, HELLO, IPXSAP, PROBE, ACK, STUB, SIAQUERY, SIAREPLY)
R1#
*Mar 1 00:28:51.867: EIGRP: Sending HELLO on Serial0/0
*Mar 1 00:28:51.867: AS 1000, Flags 0x0, Seq 0/0 idbQ 0/0 iidbQ un/rely 0/0
*Mar 1 00:28:52.931: EIGRP: Sending HELLO on Loopback1
*Mar 1 00:28:52.931: AS 1000, Flags 0x0, Seq 0/0 idbQ 0/0 iidbQ un/rely 0/0
*Mar 1 00:28:52.935: EIGRP: Received HELLO on Loopback1 nbr 10.0.1.1
*Mar 1 00:28:52.935: AS 1000, Flags 0x0, Seq 0/0 idbQ 0/0
*Mar 1 00:28:52.935: EIGRP: Packet from ourselves ignored
*Mar 1 00:28:56.031: EIGRP: Sending HELLO on Loopback11
*Mar 1 00:28:56.031: AS 1000, Flags 0x0, Seq 0/0 idbQ 0/0 iidbQ un/rely 0/0
*Mar 1 00:28:56.035: EIGRP: Received HELLO on Loopback11 nbr 10.0.11.1
*Mar 1 00:28:56.035: AS 1000, Flags 0x0, Seq 0/0 idbQ 0/0
*Mar 1 00:28:56.035: EIGRP: Packet from ourselves ignored
This output shows that Hello packets are being sent out of the S0/0, Lo1 and Lo11 interfaces as we’d expect. Note that the router ignores hello packets that it receives on in it’s loopback interfaces as it realises that these have been sent from itself.
We’ll also use the show ip protocols command to confirm we are routing for the correct networks:
R1#show ip protocols
Routing Protocol is "eigrp 1000"
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Default networks flagged in outgoing updates
Default networks accepted from incoming updates
EIGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0
EIGRP maximum hopcount 100
EIGRP maximum metric variance 1
Redistributing: eigrp 1000
EIGRP NSF-aware route hold timer is 240s
Automatic network summarization is not in effect
Maximum path: 4
Routing for Networks:
10.0.1.1/32
10.0.11.1/32
192.168.100.0/30
Routing Information Sources:
Gateway Distance Last Update
(this router) 90 00:15:51
Distance: internal 90 external 170
So at this point R1’s config is done, but it hasn’t yet formed an adjacency with R2. In order for two routers to form an adjacency, the following conditions must be met:
- the two routers must have the same EIGRP AS number configured
- the interfaces through which the two routers are exchanging EIGRP packets must be connected to the same IP subnet
- K values (used in EIGRP metric calculation) must match on both routers
Next we’ll configure EIGRP on R2:
R2(config)#router eigrp 1000
R2(config-router)#network 192.168.100.0 0.0.0.3
R2(config-router)#network 10.0.2.1 0.0.0.0
R2(config-router)#network 10.0.22.1 0.0.0.0
R2(config-router)#no auto-summary
As soon as we enter the network statement for the 192.168.100.0 network on R2 we see the R1 <–> R2 adjacency come up:
R2(config-router)# *Mar 1 00:20:34.679: %DUAL-5-NBRCHANGE: IP-EIGRP(0) 1000:
Neighbor 192.168.100.1 (Serial0/0) is up: new adjacency
R1#
*Mar 1 00:20:24.475: %DUAL-5-NBRCHANGE: IP-EIGRP(0) 1000: Neighbor 192.168.100.2
(Serial0/0) is up: new adjacency
This is because R1 is listening for EIGRP hello packets on interface S0/0 and has now received one from R2 that contains a matching AS number and K values – therefore the adjacency will form. We’ll use some extra show commands on R2 to verify the config:
R2#show ip eigrp neighbors
IP-EIGRP neighbors for process 1000
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 192.168.100.1 Se0/0 11 00:01:47 12 200 0 4
R2#show ip eigrp topology
IP-EIGRP Topology Table for AS(1000)/ID(10.0.22.1)
Codes: P - Passive, A - Active, U - Update, Q - Query, R - Reply,
r - reply Status, s - sia Status
P 10.0.11.0/24, 1 successors, FD is 2297856
via 192.168.100.1 (2297856/128256), Serial0/0
P 10.0.2.0/24, 1 successors, FD is 128256
via Connected, Loopback2
P 10.0.1.0/24, 1 successors, FD is 2297856
via 192.168.100.1 (2297856/128256), Serial0/0
P 192.168.100.0/30, 1 successors, FD is 2169856
via Connected, Serial0/0
P 10.0.22.0/24, 1 successors, FD is 128256
via Connected, Loopback22
Finally, let’s check the routing tables of each router to confirm that each one has learned about the other’s attached networks via EIGRP:
R1#show ip route eigrp
10.0.0.0/24 is subnetted, 4 subnets
D 10.0.2.0 [90/2297856] via 192.168.100.2, 00:14:28, Serial0/0
D 10.0.22.0 [90/2297856] via 192.168.100.2, 00:14:28, Serial0/0
R2#show ip route eigrp
10.0.0.0/24 is subnetted, 4 subnets
D 10.0.11.0 [90/2297856] via 192.168.100.1, 00:14:00, Serial0/0
D 10.0.1.0 [90/2297856] via 192.168.100.1, 00:14:00, Serial0/0
All looking good! In the next post I’ll cover some more EIGRP theory and config for CCNP study.
Cheers
Rich
Follow Rich on Twitter




 So…..I passed my SWITCH (642-813: Implementing Cisco IP Switched Networks) exam back in March of this year, and after a lull of 5 months I’ve decided to get back on track with my certification goals.
So…..I passed my SWITCH (642-813: Implementing Cisco IP Switched Networks) exam back in March of this year, and after a lull of 5 months I’ve decided to get back on track with my certification goals.